
Wolltest du jemals Fragen zu deinen Dokumenten, Forschungsarbeiten oder Projektdateien stellen, ohne sie in die Cloud hochzuladen? RAG (Retrieval-Augmented Generation) mit Ollama in Askimo macht es möglich. Lokale KI-Modelle wie Llama, Mistral oder Phi können Fragen zu deinen PDFs, Word-Dokumenten, Notizen und allen textbasierten Dateien beantworten - alles läuft vollständig auf deinem Rechner.
TL;DR: Ollama installieren, ein Modell wie
llama3odermistralpullen, Askimo herunterladen, ein Projekt mit deinem Dokumentenordner erstellen und mit dem Fragen beginnen. Deine Dateien werden lokal indexiert, und die KI ruft relevante Informationen ab, um deine Fragen zu beantworten - nach dem Setup kein Internet erforderlich.
Neu bei Ollama? Lies unseren Guide darüber, warum Askimo die beste Desktop-App für Ollama ist.
Warum RAG mit Ollama für deine Dokumente nutzen?
Das Problem: KI kennt deine Dateien nicht
Als ChatGPT und ähnliche KI-Assistenten aufkamen, waren sie revolutionär für allgemeine Fragen. Diese Tools sind stark in allgemeinem Wissen, weil sie mit riesigen Mengen öffentlicher Daten trainiert wurden.
Aber wer KI für seine eigentliche Arbeit nutzen wollte, stieß schnell an eine Wand:
Die Einzeldokument-Beschränkung: Früh war es möglich, ein Dokument hochzuladen und Fragen dazu zu stellen. Für schnelle Aufgaben wie “Fasse diesen Bericht zusammen” funktionierte das. Echte Arbeit erfordert aber mehr:
- Forschungsarbeiten: Du hast nicht ein Paper - du hast 20, 50 oder 100+ Papers, die du zusammenführen musst
- Unternehmensrichtlinien: Deine Organisation hat dutzende Richtliniendokumente, Handbücher und Leitfäden
- Projektdokumentation: Besprechungsnotizen, Anforderungen, technische Spezifikationen und Kundenkommunikation verteilt über Dateien
- Persönliches Wissen: Jahre von Notizen, Recherchen und Texten, auf die du zugreifen möchtest
Das tiefere Problem: Wenn du einen typischen KI-Assistenten zu deiner Arbeit befragst:
-
Allgemeine Antworten: Die KI antwortet auf Basis ihrer Trainingsdaten aus dem Internet, nicht was tatsächlich in deinen spezifischen Dateien steht.
-
Halluzinationen: Ohne Zugang zu deinen Dokumenten kann die KI Informationen erfinden, die plausibel klingen, aber nicht in deinen Dateien existieren.
-
Kein Kontext über mehrere Dateien: Du kannst nicht fragen “Was sagen all meine Forschungsarbeiten über Methodik?” Die KI hat keinen ganzheitlichen Überblick über deine Dokumentensammlung.
-
Verlorenes Wissen: All die angesammelten Notizen, Recherchen und Dokumente? Die KI kann dir nicht helfen, Muster, Verbindungen oder vergessene Erkenntnisse darin zu finden.
-
Datenschutzbedenken: Für dokumentenspezifische Hilfe müsstest du sensible Dokumente in Cloud-Dienste hochladen.
Der eigentliche Bedarf: Menschen wollen KI, die ihre Arbeit tiefgehend kennt - nicht nur ein Dokument auf einmal, sondern ihre gesamte Wissensbasis. Das ist genau das, was RAG mit Ollama löst.
Die Lösung: RAG macht lokale KI dokumentenbewusst
Mit RAG werden Ollama-Modelle zu deinem persönlichen Forschungsassistenten, der deine Dateien wirklich kennt:
- Fundierte Antworten: Antworten referenzieren deine tatsächlichen Dokumente, nicht allgemeine Informationen
- Dateigedächtnis: Die KI “erinnert sich” an alle deine Dokumente und deren Inhalt
- Sofortiger Kontext: Relevante Informationen werden automatisch abgerufen, wenn du Fragen stellst
- Vollständige Privatsphäre: Alles läuft lokal - deine Dateien verlassen nie deinen Rechner
Mehr erfahren: Für einen Vergleich von Ollama-Clients, sieh unseren Besten Ollama-Clients 2026 Guide.
Wie RAG mit Ollama funktioniert
Wenn du ein Projekt in Askimo erstellst und RAG aktivierst:
- Indexierung: Deine Dateien werden gelesen, in Chunks unterteilt und für schnelle Suche organisiert
- Speicherung: Der Index liegt auf deinem Rechner (benötigt typischerweise 10-30% deiner Dateigröße)
- Abruf: Wenn du eine Frage stellst, werden relevante Informationen automatisch gefunden
- Injektion: Diese Snippets werden der KI vor ihrer Antwort gezeigt
- Generierung: Ollama-Modelle nutzen diesen Kontext für genaue, dokumentenspezifische Antworten
All das passiert lokal - keine externen API-Aufrufe für Indexierung oder Abruf.
Technische Details? Besuche unsere RAG-Dokumentation.
Praxisnahe Anwendungsfälle
Forschung: Synthese über mehrere Papers hinweg
Die Herausforderung: Du hast 50+ Forschungsarbeiten zum Klimawandel. Traditionelle Suche findet Keywords, kann aber keine Erkenntnisse über Dokumente hinweg synthetisieren.
Mit RAG:
You: "What are the main findings across all my climate research papers?"
Llama 3: Based on your papers, three key findings emerge:1. Temperature increases correlate with CO2 levels (mentioned in 12 papers)2. Ocean acidification is accelerating faster than predicted (7 papers)3. Renewable energy adoption is cost-effective (15 papers with economic data)
Sources: climate-change-2023.pdf, renewable-study.docx, ocean-research.pdf [and 9 more]Fragen, die du stellen kannst:
- “Vergleiche die Methoden meiner Studien zu erneuerbaren Energien”
- “Welche Datensätze tauchen am häufigsten in meiner Forschungssammlung auf?”
- “Finde widersprüchliche Schlussfolgerungen zur Effizienz von Solarpanelen”
Schreiben: Verwaltung von Langformprojekten
Die Herausforderung: Dein Roman hat 30 Kapitel, Charakternotizen, Weltenbeschreibungen und Plotumrisse. Den Überblick über Details auf Hunderten von Seiten zu behalten ist schwierig.
Mit RAG:
You: "Has Elena ever mentioned being afraid of water in any chapter?"
Mistral: Yes, in chapter 7 Elena mentions she nearly drowned as a child. She alsoavoids the harbor scene in chapter 12 saying "I don't do boats." Your characternotes list this as a key personality trait stemming from her childhood incident.
Sources: chapter-07.docx, chapter-12.docx, character-profiles.mdFragen, die du stellen kannst:
- “Welche Fähigkeiten hat der Antagonist bisher gezeigt?”
- “Liste alle Orte auf, die ich im Östlichen Königreich beschrieben habe”
- “Welche Zeitlinien-Inkonsistenzen existieren zwischen Kapitel 3, 8 und 15?”
Arbeit: Schneller Zugriff auf Unternehmenswissen
Die Herausforderung: Dein Team hat hunderte Dokumente - Richtlinien, Besprechungsnotizen, Projektspezifikationen, Kundenfeedback. Spezifische Informationen zu finden kostet jede Woche Stunden.
Mit RAG:
You: "What's our policy on remote work expenses?"
Llama 3: According to the HR Policy Handbook (updated Jan 2026), employees canexpense up to $500/month for home office equipment and $150/month for internet.Receipts must be submitted within 30 days. See section 4.2 for full details.
Source: HR-Policies-2026.pdf (page 23)Fragen, die du stellen kannst:
- “Was waren die Aktionspunkte aus dem letzten Teammeeting?”
- “Finde alles Kundenfeedback, das die mobile App erwähnt”
- “Fasse die Q4 2025 Leistungskennzahlen zusammen”
RAG mit Ollama einrichten
Schritt 1: Ollama installieren
Ollama läuft lokal auf macOS, Windows und Linux.
macOS:
# Download from https://ollama.com/download/mac# Or use Homebrewbrew install ollamaLinux:
curl -fsSL https://ollama.com/install.sh | shWindows:
# Download installer from https://ollama.com/download/windowsInstallation testen:
ollama run llama3Detailliertes Ollama-Setup: Sieh unseren Ollama-Provider-Guide.
Schritt 2: Embedding-Modell pullen
RAG benötigt ein Embedding-Modell, um deine Dokumente in durchsuchbare Informationen umzuwandeln:
ollama pull nomic-embed-textDies ist Askimos Standard-Embedding-Modell für Ollama - schnell und für alle Dokumententypen geeignet.
Schritt 3: Chat-Modell pullen
Wähle ein Modell basierend auf dem Arbeitsspeicher deines Computers:
# For 8GB+ RAM - Fast and capableollama pull llama3
# For 16GB+ RAM - Excellent for complex questionsollama pull mistral
# For 4-8GB RAM - Lightweightollama pull phi3Schritt 4: Askimo installieren
Lade Askimo für deine Plattform herunter:
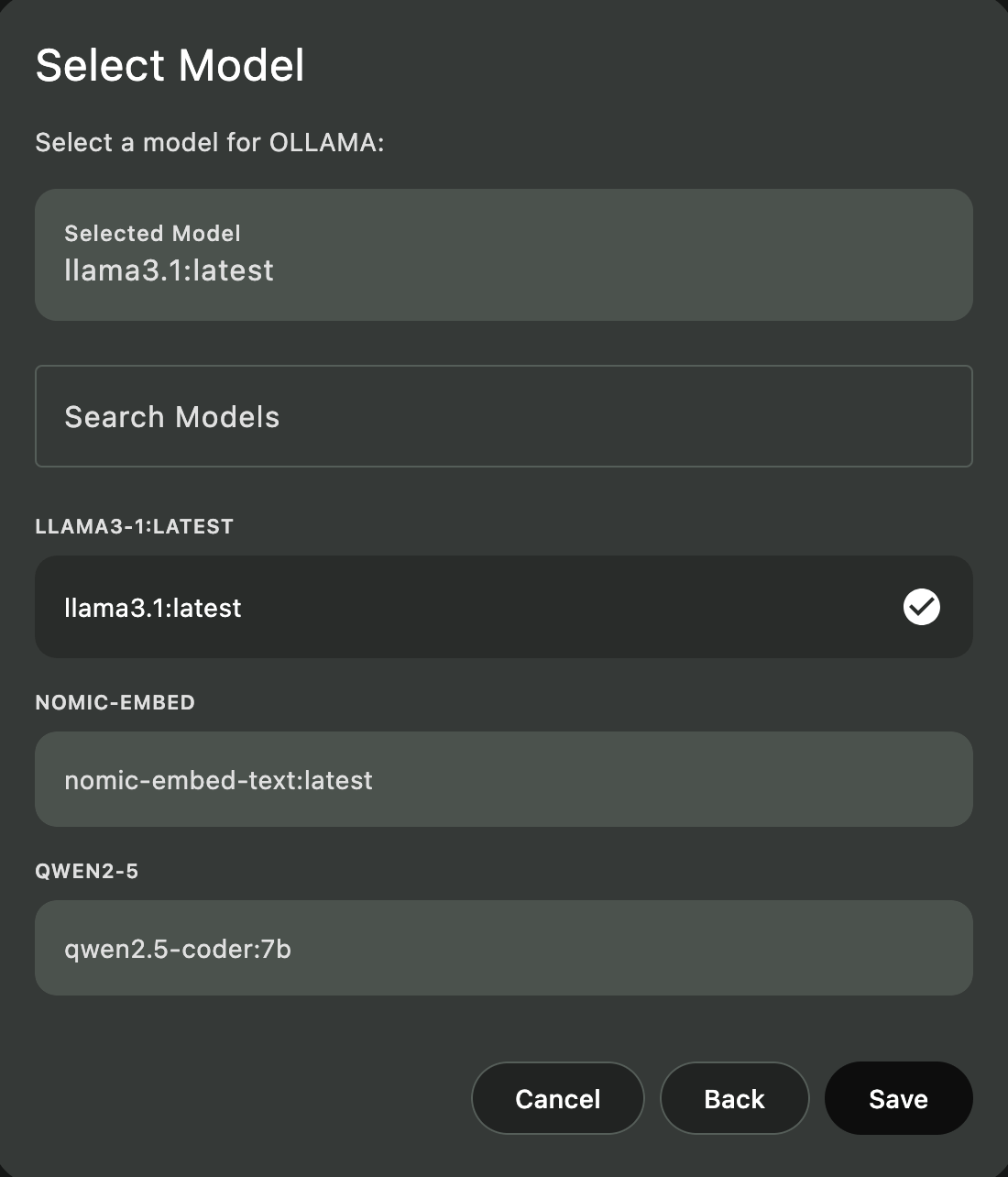
Schritt 5: Ollama in Askimo konfigurieren
- Askimo öffnen
- Zu Einstellungen → Anbieter gehen
- Ollama aktivieren
- Endpunkt auf
http://localhost:11434setzen - Chat-Modell auswählen (z.B.
llama3) - Embedding-Modell auf
nomic-embed-textsetzen
Schritt 6: Ein Projekt mit RAG erstellen
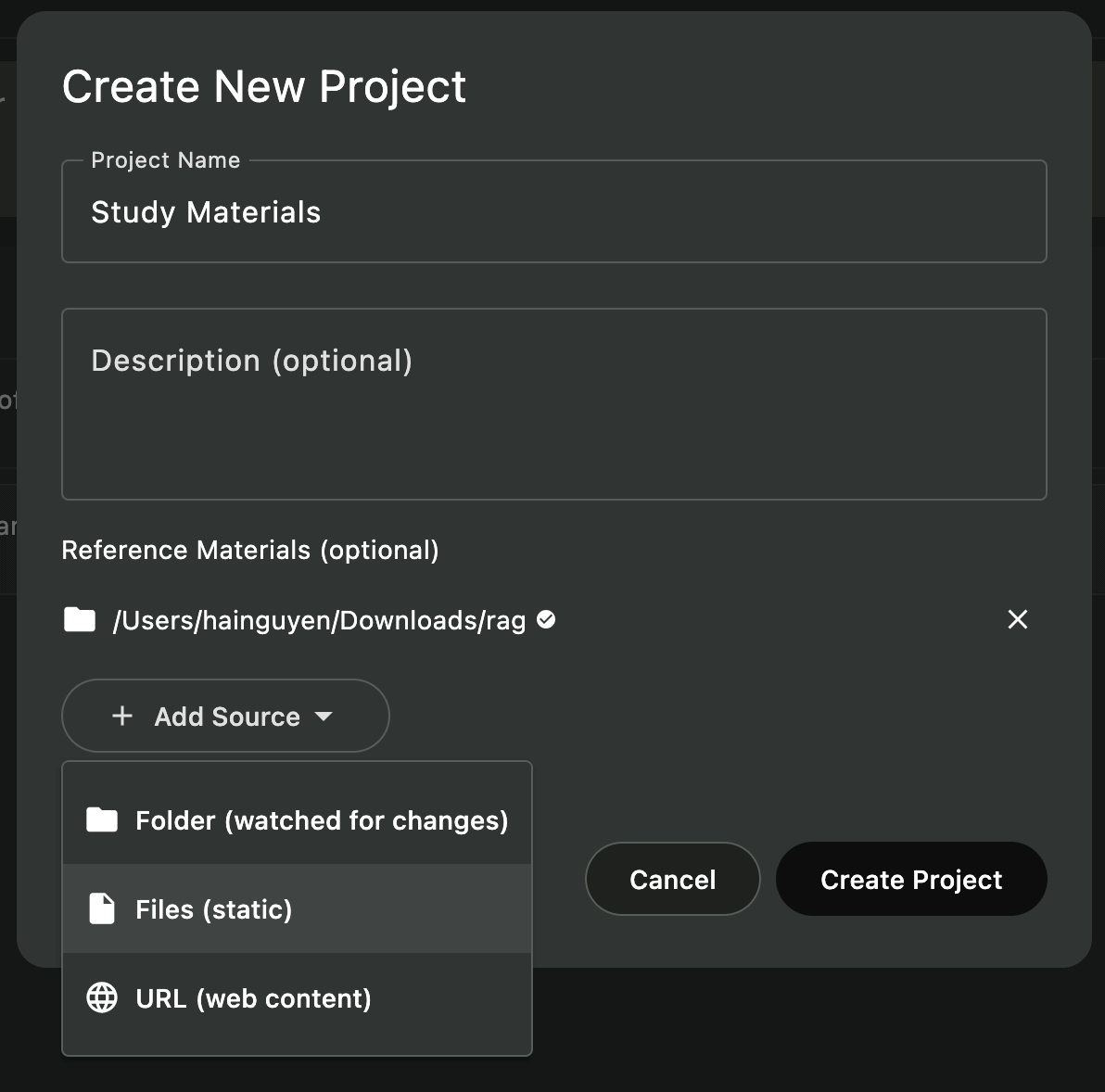
-
Projekt-Manager öffnen
- Klicke das “Projekte”-Symbol in der Seitenleiste
- Oder nutze
⌘/Ctrl + P
-
Neues Projekt erstellen
- Klicke ”+ Neues Projekt”
- Namen eingeben (z.B. “Meine Forschungsarbeiten”, “Buchnotizen”, “Lernmaterialien”)
- Klicke “Ordner auswählen” und wähle deinen Dokumentenordner
-
Automatische Indexierung
- Askimo erkennt deine Dateien automatisch
- Indexierung startet im Hintergrund
- Warte auf Abschluss (10-60 Sekunden für typische Dokumentensammlungen)
-
Mit dem Chatten beginnen
- Erstelle einen neuen Chat innerhalb des Projekts
- RAG ist automatisch aktiviert
- Stelle Fragen zu deinen Dokumenten!
Profi-Tipp: Du kannst mehrere Projekte für verschiedene Zwecke erstellen - eines für Arbeitsdokumente, eines für persönliche Recherche, eines für Lernmaterialien usw.
Was indexiert wird
Askimo indexiert deine Dateien intelligent:
Enthaltene Dateien
- Dokumente:
.pdf,.docx,.doc,.odt(Text wird automatisch extrahiert) - Tabellenkalkulationen:
.xlsx,.xls,.ods - Präsentationen:
.pptx,.ppt,.odp - Textdateien:
.txt,.md,.rtf - E-Mails:
.eml,.msg - Notizen & Texte: Markdown, Klartext, Rich Text
- Quellcode:
.js,.py,.java,.html,.css(für technische Nutzer) - Konfiguration:
.json,.yaml,.xml
Automatisch ausgeschlossen
- Systemdateien: Versteckte Dateien, temporäre Dateien
- Große Dateien: Dateien über 5 MB (für schnelle Indexierung)
- Binärdateien: Bilder, Videos, Audio (sofern keine unterstützten Dokumenttypen)
- Komprimierte Archive:
.zip,.rar,.tar
Mehr Details: Erfahre mehr über Indexierungsverhalten, Dateiausschlüsse und erweiterte Konfiguration in unserer RAG-Dokumentation.
Beispiel: Mit deinen Forschungsarbeiten chatten
Erstelle ein Projekt, das auf deinen Forschungsordner zeigt:
my-research/ ├── climate-change-2023.pdf ├── renewable-energy-study.pdf ├── notes/ │ └── literature-review.md └── data/ └── analysis-summary.pdfIndexierung dauert ca. 20 Sekunden. Dann kannst du fragen:
Du: “Was sind die Haupterkenntnisse zur Effizienz von Solarpanelen?”
Llama 3:
Laut deinen Forschungsarbeiten erreichen moderne Panels eine Effizienz von 20-22%, gegenüber 15% vor einem Jahrzehnt. Bifaziale Panels können unter optimalen Bedingungen 25% erreichen.
Sources: solar-panel-efficiency.docx, renewable-energy-study.pdf
Du: “Vergleiche Schlussfolgerungen über all meine Forschungsarbeiten zu erneuerbaren Energien”
Llama 3:
Alle deine Papers sind sich einig, dass Solar- und Windenergie die skalierbarsten Lösungen sind, die Kosten dramatisch gesunken sind und Speicherung die wichtigste Herausforderung bleibt.
Beachte, wie die KI deine tatsächlichen Dokumente referenziert, nicht allgemeine Informationen aus dem Internet.
Beispiel: Unternehmens-Wissensbank
Indexiere deine Unternehmensdokumente:
company-docs/ ├── policies/ │ ├── return-policy.pdf │ ├── shipping-policy.docx │ └── customer-service-guidelines.pdf ├── meeting-notes/ │ └── 2026-Q1-updates.docx └── procedures/ └── refund-process.pdfSofortiger Zugriff auf Unternehmenswissen:
Du: “Was ist unsere Rückgaberichtlinie für defekte Produkte?”
Llama 3:
Laut return-policy.pdf (aktualisiert Jan 2026) können defekte Produkte innerhalb von 90 Tagen mit Kaufnachweis zurückgegeben werden. Kunden erhalten eine vollständige Erstattung plus Rücksendekosten. Die refund-process.pdf vermerkt, dass Rückerstattungen innerhalb von 5-7 Werktagen bearbeitet werden.
Sources: return-policy.pdf (section 3.2), refund-process.pdf
RAG hilft deinem Team, genaue Richtlinieninformationen in Sekunden zu finden, statt durch dutzende Dateien zu suchen.
Erweiterte RAG-Funktionen
Mehrere Projekte für verschiedene Themen
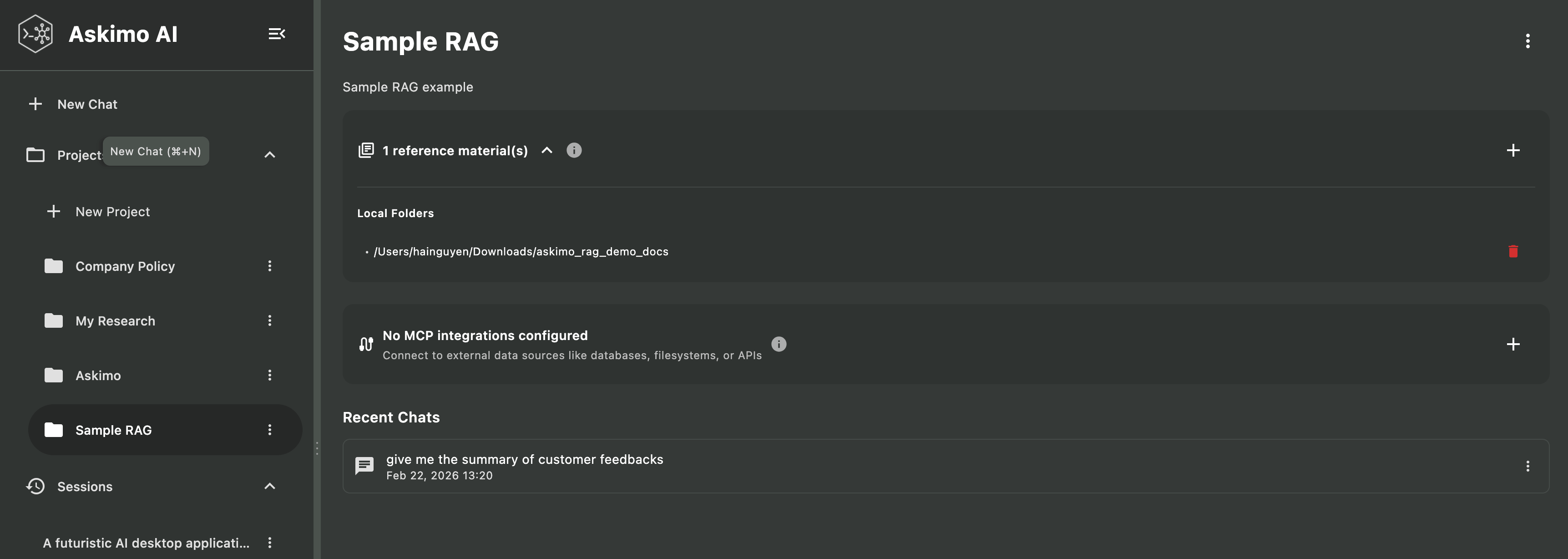
Organisiere deine Dokumente in separate Projekte:
- Arbeitsdokumente: Geschäftsberichte, Besprechungsnotizen, Kundendateien
- Persönliche Recherche: Hobbys, Interessen, Lernmaterialien
- Akademische Arbeit: Lernmaterialien, Forschungsarbeiten, Abschlussnotizen
- Kreativprojekte: Schreiben, Kunstnotizen, Brainstorming-Dokumente
Jedes Projekt hat seinen eigenen isolierten Index, sodass Abfragen nur relevante Dokumente durchsuchen.
Automatische Updates
Askimo erkennt Dateiänderungen automatisch:
- Datei geändert: Indexiert nur diese Datei neu
- Datei hinzugefügt: Zum Index hinzugefügt
- Datei gelöscht: Aus dem Index entfernt
Kein manueller Eingriff für alltägliche Bearbeitungen nötig.
Benutzerdefinierte Embedding-Modelle
Für fortgeschrittene Nutzer, die experimentieren möchten:
# Pull a specialized embedding modelollama pull mxbai-embed-large
# In Askimo Settings → Providers → Ollama# Change embedding model to: mxbai-embed-largeTechnischer Tiefeinstieg: Erfahre mehr über Embedding-Modelle, Vektorsuche und Indexierungsarchitektur in unserer umfassenden RAG-Dokumentation.
Leistungstipps
Das richtige Modell für deinen Computer wählen
| Arbeitsspeicher deines Computers | Empfohlenes Modell | Am besten für |
|---|---|---|
| 4-8 GB | phi3 | Schnelle Fragen, einfache Dokumente |
| 8-16 GB | llama3 | Allgemein, Recherche, Schreiben |
| 16+ GB | mistral | Komplexe Analysen, lange Dokumente |
| 32+ GB | deepseek-coder | Große Dokumentensammlungen |
Spezifische Fragen stellen
Statt breite Fragen zu stellen, sei spezifisch:
-
❌ “Erzähl mir von diesem Projekt”
-
✅ “Was sind die Haupterkenntnisse in den Klimaforschungsarbeiten?”
-
❌ “Fasse alles zusammen”
-
✅ “Welche Methodik wurde in der Studie von 2023 verwendet?”
RAG vs. traditionelle Dokumentensuche
| Funktion | Datei-Explorer-Suche | PDF-Reader-Suche | Askimo RAG mit Ollama |
|---|---|---|---|
| Stichwortsuche | ✅ Grundlegend | ✅ Schnell | ✅ Sofort in allen Dateien |
| Semantische Suche | ❌ Nein | ❌ Nein | ✅ Versteht Bedeutung |
| Natürliche Sprache | ❌ Nein | ❌ Nein | ✅ Fragen in natürlicher Sprache |
| Dokumentübergreifend | ❌ Jeweils ein Dokument | ❌ Jeweils ein Dokument | ✅ Durchsucht alle Dokumente |
| Kontextverständnis | ❌ Nein | ❌ Nein | ✅ Versteht Beziehungen |
| Antworterstellung | ❌ Nein | ❌ Nein | ✅ Erklärt und fasst zusammen |
| Datenschutz | ✅ Lokal | ✅ Lokal | ✅ Vollständig lokal |
Datenschutz & Sicherheit
Alles bleibt lokal
- Indexierung: Läuft auf deinem Rechner mit Lucene
- Embeddings: Lokal von Ollama generiert
- Chat: Ollama-Modelle laufen auf deiner Hardware
- Speicherung: Index-Dateien bleiben in
~/.askimo/
Keine externen Abhängigkeiten
Sobald du Ollama-Modelle gepullt hast:
- Funktioniert vollständig offline
- Keine API-Aufrufe an externe Dienste
- Keine Daten verlassen deinen Rechner
Projektisolierung
Jedes Projekt hat seinen eigenen isolierten Index:
- Projekte können nicht auf die Daten anderer zugreifen
- Löschen eines Projekts entfernt seinen Index
- Kein projektübergreifendes Datenleck
Fehlerbehebung
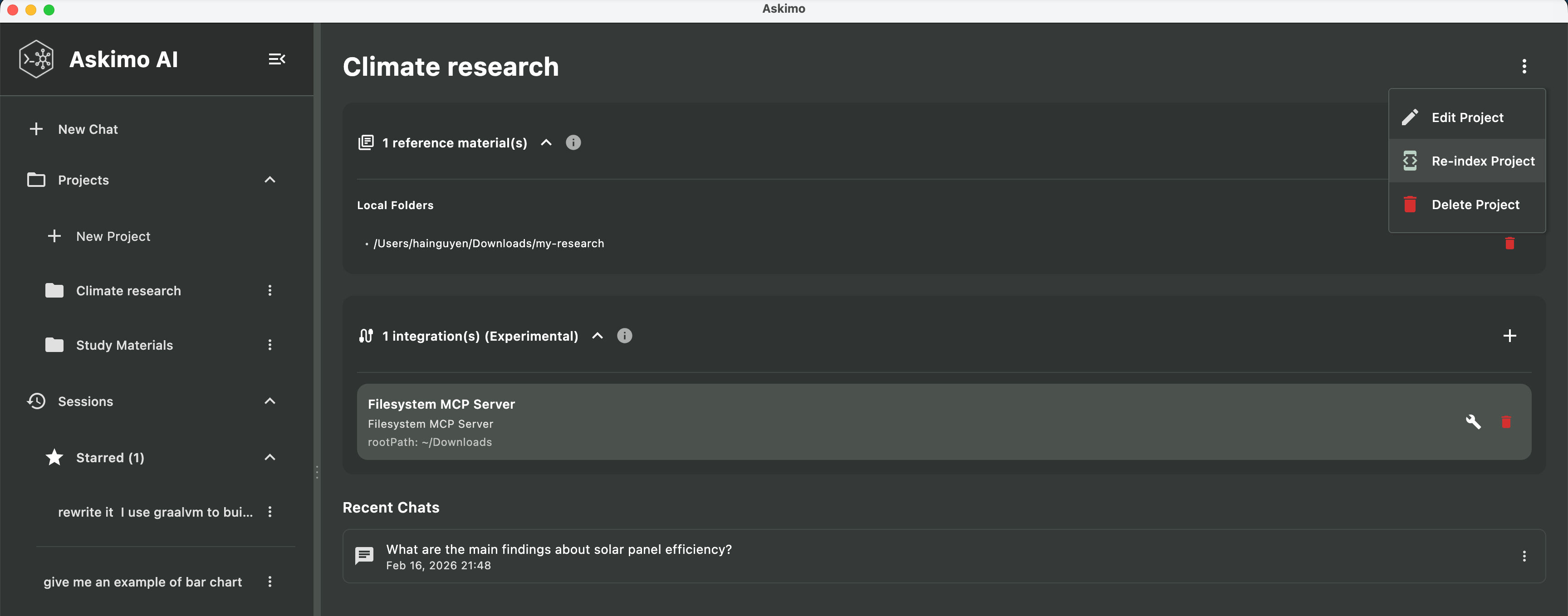
”KI scheint meine Dokumente nicht zu kennen”
Mögliche Ursachen:
- Projekt noch nicht indexiert: Überprüfe den Status im Projektbereich
- Dateien nicht unterstützt: Stelle sicher, dass du unterstützte Dateitypen verwendest (PDF, DOCX, TXT usw.)
- Dateien zu groß: Dateien über 5 MB werden übersprungen
Lösung:
- Warte auf Abschluss der Indexierung (Status-Anzeige prüfen)
- Versuche Neuindexierung: Projekteinstellungen → “Projekt neu indexieren”
- Stelle sicher, dass RAG für deinen Chat aktiviert ist
Langsame Indexierung
Mögliche Ursachen:
- Sehr große Dokumentensammlungen (1.000+ Dateien)
- Langsame Festplatte
- Viele große PDF-Dateien
Lösung:
- Geduld - die erste Indexierung dauert, passiert aber nur einmal
- Zukünftige Updates sind viel schneller (nur geänderte Dateien werden neu indexiert)
- Erwäge, in kleinere Projekte zu organisieren, wenn du 10.000+ Dateien hast
Arbeitsspeicher läuft voll
Mögliche Ursachen:
- Modell ist zu groß für deinen Computer
- Zu viele Anwendungen laufen
Lösung:
- Verwende ein kleineres Modell (
phi3stattmistral) - Schließe andere speicherintensive Anwendungen
- Starte deinen Computer neu, um Speicher freizugeben
Mehr Hilfe nötig? Frage in unseren GitHub-Diskussionen.
Was du mit RAG tun kannst
RAG mit Ollama in Askimo eröffnet neue Möglichkeiten:
- Forschung: Informationen schnell über dutzende Papers und Artikel finden
- Schreiben: Charaktere, Handlungspunkte und Recherchen für deine Bücher im Blick behalten
- Lernen: Effektiver studieren durch Fragen zu Notizen und Materialien
- Arbeit: Informationen in Berichten, Besprechungsnotizen und Projektdokumentation finden
- Persönlich: Rezepte, Reiserecherchen, Hobbynotizen organisieren
Alles während deine Dokumente privat und lokal bleiben - nichts verlässt deinen Computer.
Häufig gestellte Fragen
Funktioniert RAG mit Ollama offline? Ja, vollständig. Sobald Ollama-Modelle heruntergeladen und dein Projekt indexiert ist, läuft alles ohne Internetverbindung. Indexierung, Abruf und KI-Antworten finden alle auf deinem Rechner statt. Es gibt keine externen API-Aufrufe in irgendeiner Phase.
Sind meine Daten privat bei der Nutzung von RAG mit Ollama? Ja. Deine Dokumente verlassen deinen Rechner nie. Indexierung erfolgt lokal mit Apache Lucene, Embeddings werden von einem lokalen Ollama-Modell generiert, und das Chat-Modell läuft auf deiner eigenen Hardware. Nichts wird an einen Cloud-Dienst gesendet.
Welche Dateitypen unterstützt Askimo RAG? PDFs, Word-Dokumente (.docx, .doc), Tabellenkalkulationen (.xlsx, .xls), Präsentationen (.pptx), Klartext, Markdown, Rich-Text-Dateien, E-Mails und Quellcode-Dateien. Dateien über 5 MB und Binärdateien (Bilder, Video, Audio) werden automatisch ausgeschlossen.
Wie unterscheidet sich RAG mit Ollama vom Hochladen eines Dokuments bei ChatGPT? Drei Hauptunterschiede: Datenschutz (Dateien verlassen deinen Rechner nie), Skalierung (RAG durchsucht hunderte Dokumente gleichzeitig, nicht nur eines) und Genauigkeit (Antworten basieren auf deinen tatsächlichen Dokumenten statt Trainingsdaten, was Halluzinationen deutlich reduziert).
Wie lange dauert die Indexierung? Für einen typischen Ordner mit 50-100 Dokumenten dauert die erste Indexierung 10-60 Sekunden. Danach werden nur geänderte oder neue Dateien automatisch neu indexiert, sodass Updates nahezu sofort erfolgen.
Welches Ollama-Modell eignet sich am besten für RAG?
Für die meisten Nutzer bieten Llama oder Mistral die beste Balance aus Geschwindigkeit und Antwortqualität. Bei weniger als 8 GB RAM verwende stattdessen Phi. Für das Embedding-Modell ist nomic-embed-text der empfohlene Standard.
Mehr über Askimo & Ollama erfahren
Bereit, mehr Funktionen zu entdecken?
- Askimo mit Ollama: Der beste Desktop für lokale KI - Vollständiger Guide zur Nutzung von Askimo als Ollama-GUI
- Beste Ollama-Clients 2026 - Vergleiche Ollama-Desktop-Clients
- Ollama-Provider-Einrichtung - Detaillierter Konfigurationsguide für Ollama in Askimo
- RAG-Technische Dokumentation - Tiefer Einblick in RAG-Indexierung und Abruf
Probiere Askimo heute aus: 👉 https://askimo.chat
Gib dem Projekt einen Stern: 👉 https://github.com/haiphucnguyen/askimo
Fragen oder Feedback? Öffne ein Issue auf GitHub oder schreib in unseren Community-Diskussionen. Wir würden gerne hören, wie du RAG mit deinen Dokumenten nutzt!