
您是否曾想过,无需将文件上传至云端,就能直接向文档、研究论文或项目文件提问?Askimo中的Ollama RAG(检索增强生成)让这成为可能。Llama、Mistral、Phi等本地AI模型可以回答关于您的PDF、Word文档、笔记和任何文本文件的问题,一切都在您的设备上本地运行。
快速入门:安装Ollama,拉取
llama3或mistral等模型,下载Askimo,创建指向文档文件夹的项目,然后开始提问。文件在本地建立索引,AI会检索相关信息来回答您的问题。设置完成后无需联网。
Ollama新手? 查看我们的指南:为什么Askimo是最佳Ollama桌面应用。
为什么要将RAG与Ollama结合用于文档?
问题:AI不了解您的文件
ChatGPT等AI基于海量公开数据训练,擅长回答通用知识问题。但当用户尝试将AI应用于实际工作时,往往会遇到瓶颈:
- 研究论文:不是一篇,而是需要综合分析的20篇、50篇甚至100多篇
- 公司政策:组织有几十份政策文件、操作手册和指南
- 项目文档:会议记录、需求文档、技术规范分散在各个文件中
- 个人知识:多年积累的笔记、研究和写作需要随时参考
普通AI基于训练数据而非您的具体文件作答;可能编造听起来合理但不存在的信息(幻觉);无法跨多个文件同时检索;处理敏感文件还需上传至云端。
解决方案:RAG让本地AI理解文档
有了RAG,Ollama模型成为真正了解您文件的个人研究助手:
- 有依据的回答:引用您的实际文档,而非通用信息
- 文件记忆:AI”记忆”所有文档及其内容
- 即时上下文:提问时自动检索相关信息
- 完全私密:一切在本地运行,文件永不离开您的设备
了解更多:查看2026年最佳Ollama客户端指南。
RAG与Ollama的工作原理
在Askimo中创建项目并启用RAG时:
- 索引:文件被读取、分割成块,并为快速检索进行整理
- 存储:索引保存在您的设备上(通常占文件大小的10-30%)
- 检索:提问时自动找到相关信息
- 注入:这些片段在AI回答前展示给它
- 生成:Ollama模型利用这些上下文给出准确、具体的回答
所有操作均在本地完成,索引和检索均无需外部API调用。
实际应用场景
研究:跨多篇论文综合分析
You: "What are the main findings across all my climate research papers?"
Llama 3: Based on your papers, three key findings emerge:1. Temperature increases correlate with CO2 levels (mentioned in 12 papers)2. Ocean acidification is accelerating faster than predicted (7 papers)3. Renewable energy adoption is cost-effective (15 papers with economic data)
Sources: climate-change-2023.pdf, renewable-study.docx, ocean-research.pdf [and 9 more]您可以提问的示例:
- “比较我可再生能源研究中使用的方法论”
- “找出关于太阳能板效率的相互矛盾的结论”
写作:管理长篇项目
You: "Has Elena ever mentioned being afraid of water in any chapter?"
Mistral: Yes, in chapter 7 Elena mentions she nearly drowned as a child. She alsoavoids the harbor scene in chapter 12 saying "I don't do boats." Your characternotes list this as a key personality trait stemming from her childhood incident.
Sources: chapter-07.docx, chapter-12.docx, character-profiles.md工作:快速访问公司知识
You: "What's our policy on remote work expenses?"
Llama 3: According to the HR Policy Handbook (updated Jan 2026), employees canexpense up to $500/month for home office equipment and $150/month for internet.Receipts must be submitted within 30 days. See section 4.2 for full details.
Source: HR-Policies-2026.pdf (page 23)设置Ollama与RAG
第一步:安装Ollama
macOS:
brew install ollamaLinux:
curl -fsSL https://ollama.com/install.sh | shWindows: 从ollama.com/download/windows下载安装程序
测试安装:
ollama run llama3第二步:拉取嵌入模型
ollama pull nomic-embed-text第三步:拉取聊天模型
# 8GB+ 内存 - 快速且功能强大ollama pull llama3
# 16GB+ 内存 - 适合复杂问题ollama pull mistral
# 4-8GB 内存 - 轻量级ollama pull phi3第四步:安装Askimo
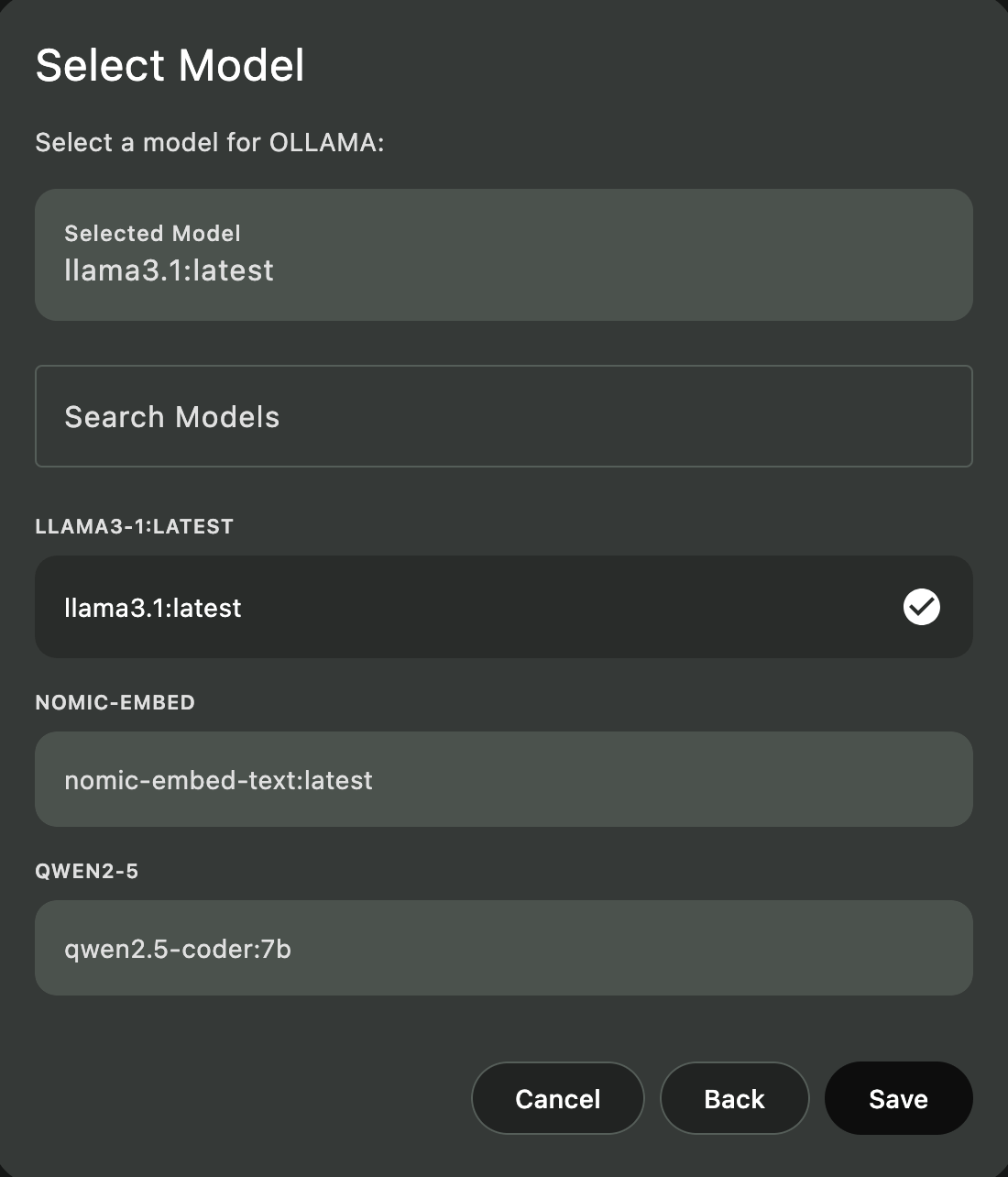
第五步:在Askimo中配置Ollama
- 打开Askimo
- 前往设置 > 提供商
- 启用Ollama
- 设置端点为
http://localhost:11434 - 选择聊天模型(如
llama3) - 设置嵌入模型为
nomic-embed-text
第六步:创建带RAG的项目
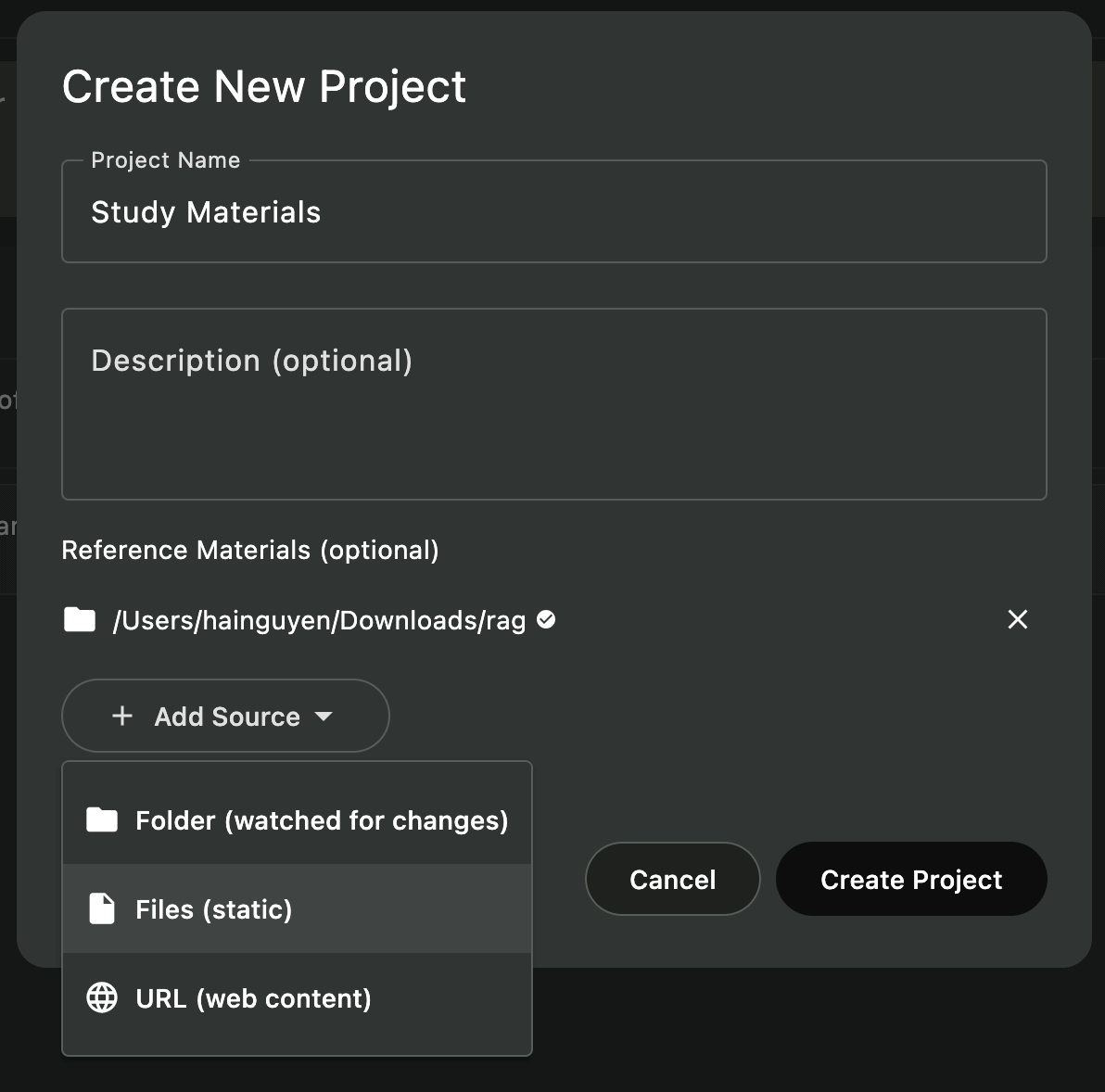
- 点击侧边栏的”项目”图标或使用
Cmd/Ctrl + P - 点击”+ 新建项目”,输入名称,选择文档文件夹
- 等待自动索引完成(10-60秒)
- 在项目中创建新对话并开始提问
提示:可以为不同用途创建多个项目,如工作文档、个人研究、学习资料等。
哪些文件会被索引
支持格式: .pdf, .docx, .doc, .odt, .xlsx, .xls, .ods, .pptx, .ppt, .txt, .md, .rtf, .eml, .msg, .js, .py, .java, .html, .css, .json, .yaml, .xml
自动排除: 隐藏/临时文件、超过5MB的文件、图片/视频/音频、压缩文件(.zip, .rar, .tar)
高级RAG功能
针对不同主题的多个项目
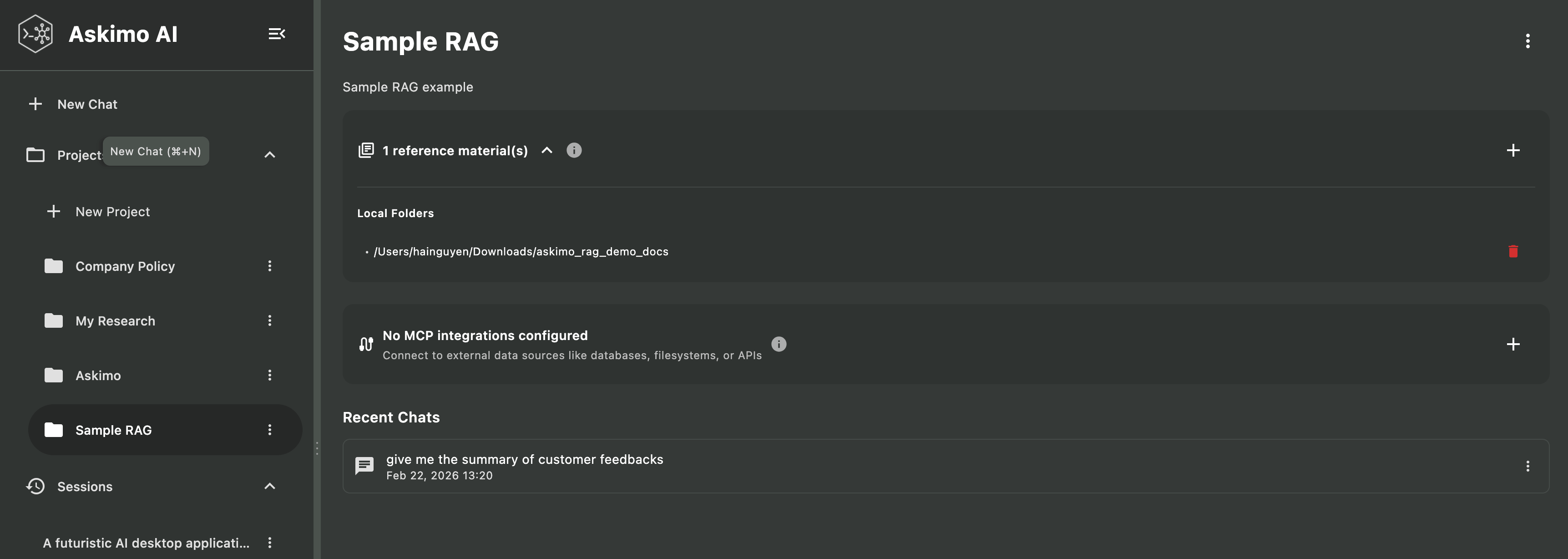
- 工作文档:业务报告、会议记录、客户文件
- 个人研究:兴趣爱好、学习资料
- 学术研究:研究论文、学习资料、论文笔记
- 创意项目:写作草稿、创意笔记
每个项目有独立的索引,查询只搜索相关文档。
自动更新
- 文件修改:仅对该文件重新索引
- 文件添加:添加到索引
- 文件删除:从索引中移除
自定义嵌入模型
ollama pull mxbai-embed-large# 在Askimo设置 > 提供商 > Ollama中更改嵌入模型性能技巧
根据电脑选择合适的模型
| 内存 | 推荐模型 | 最适合 |
|---|---|---|
| 4-8 GB | phi3 | 快速问答、简单文档 |
| 8-16 GB | llama3 | 通用、研究、写作 |
| 16+ GB | mistral | 复杂分析、长文档 |
| 32+ GB | deepseek-coder | 大型文档集合 |
RAG与传统文档搜索对比
| 功能 | 文件管理器搜索 | PDF阅读器搜索 | Askimo RAG + Ollama |
|---|---|---|---|
| 关键词搜索 | 基础 | 快速 | 所有文件即时搜索 |
| 语义搜索 | 无 | 无 | 理解含义 |
| 自然语言 | 无 | 无 | 支持自然语言提问 |
| 跨文档 | 一次一个 | 一次一个 | 同时搜索所有文档 |
| 生成答案 | 无 | 无 | 解释和总结 |
| 隐私保护 | 本地 | 本地 | 完全本地 |
隐私与安全
- 索引:在您的设备上使用Lucene完成
- 嵌入:由Ollama在本地生成
- 对话:Ollama模型在您的硬件上运行
- 存储:索引文件保存在
~/.askimo/
拉取Ollama模型后完全离线运行,数据不离开您的设备。
故障排除
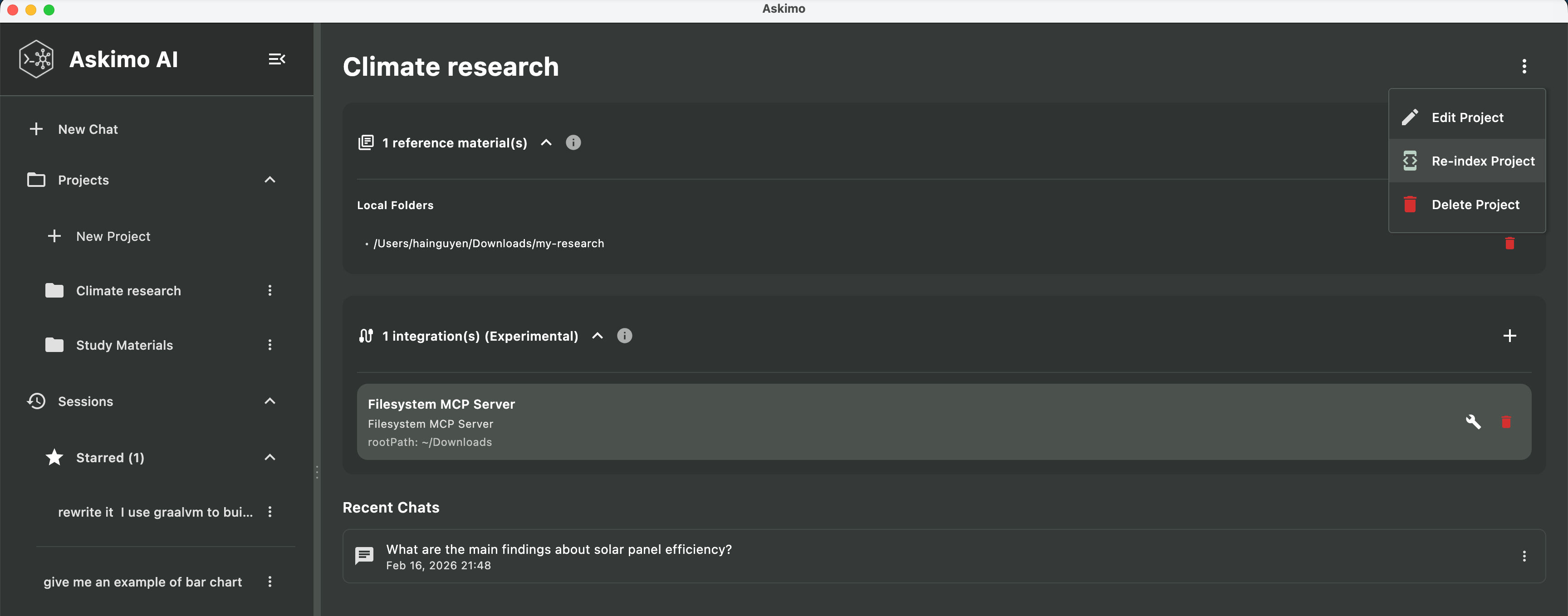
”AI似乎不了解我的文档”
- 检查项目视图中的索引状态
- 尝试重新索引:项目设置 > “重新索引项目”
- 确认使用支持的文件格式(超过5MB的文件会被跳过)
索引速度慢
- 耐心等待,初次索引只需一次
- 后续更新只重新索引变更文件,速度更快
- 文件超过10,000个时考虑拆分为更小的项目
内存不足
- 使用更小的模型(用
phi3替代mistral) - 关闭其他占用内存的应用
- 重启电脑释放内存
需要更多帮助? 在GitHub讨论中提问。
使用RAG可以做什么
- 研究:快速从数十篇论文和文章中找到信息
- 写作:追踪书中的人物、情节和研究资料
- 学习:向笔记和资料提问,更有效地学习
- 工作:从报告、会议记录和项目文档中找到信息
- 个人:整理食谱、旅行研究、兴趣爱好笔记
所有文档保持私密和本地化,没有任何内容离开您的电脑。
常见问题
Ollama的RAG可以离线工作吗? 可以,完全可以。下载模型并建立项目索引后,一切无需联网运行。任何阶段都没有外部API调用。
使用RAG和Ollama时,我的数据是否安全? 是的。您的文档绝不离开您的设备。索引通过Apache Lucene在本地完成,嵌入由本地Ollama模型生成,聊天模型在您自己的硬件上运行。不向任何云服务发送任何内容。
Askimo RAG支持哪些文件格式? PDF、Word文档(.docx, .doc)、表格(.xlsx, .xls)、演示文稿(.pptx)、纯文本、Markdown、RTF、邮件和源代码文件。超过5MB的文件和二进制文件(图片、视频、音频)会自动排除。
Ollama的RAG与向ChatGPT上传文档有何不同? 三个关键区别:隐私(文件不离开设备)、规模(RAG同时搜索数百个文档,而非一个)、准确性(基于实际文档的答案而非训练数据,大幅减少幻觉)。
索引需要多长时间? 对于50-100个文档的典型文件夹,初次索引需要10-60秒。之后只有变更或新增的文件会自动重新索引,更新几乎是即时的。
RAG最适合哪款Ollama模型?
对大多数用户来说,Llama或Mistral在速度和回答质量之间取得最佳平衡。内存不足8GB时使用Phi。嵌入模型推荐使用nomic-embed-text作为默认值。
深入了解Askimo和Ollama
立即试用Askimo:👉 https://askimo.chat
在GitHub上点赞项目:👉 https://github.com/haiphucnguyen/askimo
有问题或反馈? 在GitHub上提issue或加入社区讨论。期待听到您使用RAG处理文档的心得!